Obr.1.1
Operační systém TUOX koncepčně vychází z OS UNIX, je však postaven modulárně. Cílem projektu je dosáhnout alespoň omezenou přenositelnost zdrojového kódu ze systému UNIX V7.
Narozdíl od monolitického UNIXu je TUOX sbírkou relativně samostatných systémových procesů - tasků a serverů. Vzhledem k řadě vlastností, které jsou společné taskům, serverům i uživatelským procesům budeme v případech, kdy nebude přesné rozlišení nutné, nazývat všechny tyto entity slovem procesy.
Tasky jsou procesy, které obsahují zejména ovladače zařízení. Uživatelské procesy a servery běží v oddělených adresových prostorech, tasky jsou slinkovány do společného adresového prostoru s jádrem. Spojení adresového prostoru tasků nás však nesmí svádět k tomu, abychom na ně nahlíželi jinak než na ostatní procesy a nerespektovali jejich vzájemnou nezávislost. Skutečně, na tasky se díváme jako na nezávislé moduly jak z pohledu meziprocesové komunikace, tak jejich plánování. Spojení adresového prostoru je provedeno zejména pro dosažení alespoň teoretické přenositelnosti na procesory, které rozlišují běh v režimu uživatelském a systémovém, který dovoluje provádění privilegovaných instrukcí. Takovýchto instrukcí samozřejmě využívá jak jádro, tak ovladače zařízení.
Servery jsou procesy systémového charakteru (jako souborový systém a správce paměti), na které však jádro nahlíží stejně jako na uživatelské procesy.
Přidělování času procesoru (time slicing) uživatelským procesům a taskům se děje na základě dále popsaného prioritního mechanismu. Pro uživatelské procesy je multitasking preemptivní (mechanismus „round robin" po časových kvantech), tasky a servery běží do té doby, než se samy vzdají řízení. Z toho plyne, že každý task musí po aktivaci (zprávou, hardwarovým přerušením) vykonat požadovanou činnost v co nejkratší době. Běh serverů může být přerušen naplánováním tasku, časové kvantum se však na ně nevztahuje.
Komunikace mezi jednotlivými procesy a tasky probíhá výhradně prostřednictvím předávání zpráv a to i u tasků, které běží ve společném adresovém prostoru.
Na úrovni jádra je implementován mechanismus přidělování procesoru procesům a ovladače jednotlivých zařízení. Řeší se zde rovněž vše, co má co do činění s obsluhou přerušení. Souborový systém (FS-File System) a paměťový manažer (MM-Memory Manager) jsou řešeny servery. Služby systému, které jsou k dispozici uživatelským procesům (resp. programům v nich běžících) jsou implementovány ve FS a MM. Koncepce serverů přispívá ke větší modularitě a přehlednosti systému.
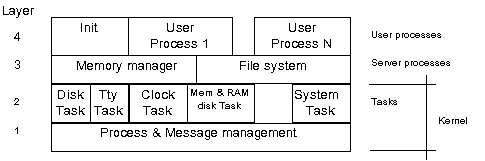
Abychom si lépe ujasnili návaznosti procesů a tasků, rozdělíme je do vrstev podle obr.1.1. Vrstvy 1 a 2 jsou zkompilovány do společného modulu a tvoří jádro. Z hlediska jádra vrstvy 3 a 4 v podstatě splývají. Části vrstvy 1 jsou napsány v assembleru, zbytek kódu systému v C. Spojení vrstev 1 a 2 má své opodstatnění: jelikož obě musí mít přímý přístup k hardwarovým prostředkům, běžely by na procesorech, které toto hardwarově podporují, v módu jádra, zatímco ostatní procesy by běžely v módu uživatelském.
Obr.1.1
Podobně jako v UNIXu existuje mezi procesy TUOXu hierarchický vztah, kdy každý proces má svého rodiče a může vytvářet potomky, tzv. dětské procesy (child processes). Stav systému vzhledem ke spuštěným procesům je v každém okamžiku zachytitelný stromem procesů. Kořenem tohoto stromu je proces Init (povšimněme si jej na obr.1.1 ve vrstvě 4). Narozdíl od ostatních procesů, které vznikají vždy štěpením (fork) svého rodiče, je Init vytvořen uměle během zavádění systému.
Při zahájení práce systému je jediným existujícím procesem Init. Init přečte tabulku terminálů (/etc/ttys) a (rozštěpením) vytvoří proces login pro každý terminál. Vstup a výstup každého z nich bude nasměrován na soubor reprezentující ovladač příslušného terminálu. Po přihlášení uživatele na některém terminálu bude image procesu login nahrazena kódem shellu, který je danému uživateli přiřazen (/etc/passwd). Shell zahájí komunikace s uživatelem a stane se rodičem veškerých procesů, které uživatel spouští.
V okamžiku, kdy proces skončí (dobrovolně voláním exit() nebo nuceně zasláním signálu kill) je vyloučen z dalšího plánování, avšak stále zůstává v paměti ve stavu ZOMBIE. V tomto stavu setrvá do té doby, než jeho rodič převezme voláním wait() návratový kód ukončeného procesu (ten byl zadán jako parametr volání exit()). Z toho plyne, že je nezbytné zajistit, aby každý proces měl stále určeného rodiče (pokud by totiž rodič skončil dříve než potomek, nikdo by jeho návratový kód nepřebral a proces bu navždy zůstal nečinný v paměti). Proto se vždy při ukončování procesu testuje, zda má proces potomky a pokud ano, ustanoví se jejich rodičem proces Init. Procesy, které takto byly převedeny přímo pod proces Init nazýváme sirotčí (orphan processes). Proces Init poté, co rozštěpí login procesy pro všechny terminály již nedělá nic jiného, než čeká ve volání wait() na okamžik, až skončí některý z jeho adoptovaných dětských procesů, aby mohl převzít jeho návratový kód a umožnit odstranění tohoto zombie procesu z paměti.
Hierarchizace procesů se využívá v mnoha mechanismech TUOXu - od zasílání signálů mezi procesy přes dědění prostředí a otevřených souborů od rodičovských procesů až po mechanismus přesměrování vstupu a výstupu procesů a vytváření kolon.
Procesy (a tasky) mezi sebou vzájemně komunikují prostřednictvím zpráv. Doručování zpráv se děje mechanismem "rendez-vous", což současně elegantně řeší problém synchronizace procesů. Pro zajištění komunikace poskytuje jádro dvě základní primitiva (funkce), třetí je jejich kombinací: send, receive a send_recv. Primitiva send umožňuje zaslat zprávu určenému procesu, primitiva recv naopak čeká na přijetí zprávy od některého procesu (nebo od libovolného procesu). Knihovny funkcí připojované k uživatelským programům používají zásadně primitivy send_recv, která zašle zprávu určenému procesu (serveru) s tím, že čeká na odpověď od tohoto procesu. Kromě identifikace procesu, se kterým se prostřednictvím zprávy komunikuje, se při volání uvedených primitiv specifikuje také adresa, na které je uložena předávaná zpráva. Na formátu zprávy a její interpretaci se musejí shodnout komunikující procesy, z hlediska jádra není podstatná. Společné je pouze pole sender, ze kterého příjemce pozná odesílatele zprávy.
Způsob, kterým mechanismus "rendez-vous" zabezpečuje synchronizaci procesů je následující. Jestliže proces A hodlá zaslat zprávu procesu B, vyvolá primitivu send(B,msg). Pokud je proces B ochoten zprávu převzít okamžitě, je mu doručena a proces A pokračuje dále. Je-li však proces B zaneprázdněn jinou činností a zprávu od A převzít nehodlá, zůstane A zablokován do té doby, než B bude ochoten jeho zprávu převzít. Pod pojmem zablokování si představujme stav, kdy plánovač procesů zablokovanému procesu nepřiděluje časová kvanta. Jádro si k procesu B (do tabulky procesů) poznamená, že proces A čeká na okamžik, až B přijme jeho zprávu. Jelikož zpráva může být procesu zaslána současně od několika jiných různých procesů, uchovává každý z procesů frontu procesů, které čekají na okamžik, kdy jejich zprávu bude schopen převzít. Ve chvíli, kdy proces B dokončí právě prováděnou činnost a je schopen vyřídit zprávu od dalšího procesu, volá primitivu receive. Jestliže ve frontě čekal nějaký proces, od kterého je B ochoten zprávu přijmout (ten byl při volání receive zadán jako požadovaný odesílatel, nebo je akceptována zpráva od kohokoli), zpráva se překopíruje do adresového prostoru B a proces, který zprávu zaslal se odblokuje (a odstraní ze fronty čekajících).
Je užitečné si všimnout, že tento mechanismus synchronizace je výhodný zejména u serverů, tj. entit, které vykonávají akce v závislosti na požadavcích konkurujících si klientů. Požadavky klientů se ve formě zpráv hromadí ve frontě, odkud je server vybírá a uskutečňuje. Do vyřízení každého požadavku je příslušný klient zablokován. Takovýto princip je užitečný především pro serializaci požadavků a operace nad sdílenými prostředky (např. diskovými zařízeními), jelikož nás ušetří mnoha problémů se synchronizací a stanovování kritických sekcí kódu, do kterých bychom zabředli pokud bychom synchronizaci řešili obecně nebo pokud by systém měl monolitickou strukturu.
Ačkoli je mechanismus doručování zpráv v podobě, ve které jsme jej popsali, zcela obecný, vnáší TUOX jedno dodatečné omezení: komunikovat spolu smějí jen dva procesy bezprostředně navazujících vrstev nebo procesy ve stejné vrstvě. Tím mj. zabraňujeme uživatelským procesům komunikovat přímo s ovladači zařízení a ostatními systémovými tasky, což je vzhledem k zabezpečení před nekorektními aplikacemi (resp. knihovnami funkcí) nezbytné.
Struktura zprávy odpovídá následující deklaraci:
#define M3_STRING 14
typedef struct {int m1i1, m1i2, m1i3; char *m1p1, *m1p2, *m1p3;} mess_1;
typedef struct {int m2i1, m2i2, m2i3; long m2l1, m2l2; char *m2p1;} mess_2;
typedef struct {int m3i1, m3i2; char *m3p1; char m3ca1[M3_STRING];} mess_3;
typedef struct {long m4l1, m4l2, m4l3, m4l4, m4l5;} mess_4;
typedef struct {char m5c1, m5c2; int m5i1, m5i2; long m5l1, m5l2, m5l3;}mess_5;
typedef struct {int m6i1, m6i2, m6i3; long m6l1; sighandler_t m6f1;} mess_6;
typedef struct { /* used for messaging with character/block devices */
int device; /* minor dev nr */
int proc_nr; /* process requesting I/O */
unsigned int count; /* # of bytes required */
unsigned long position; /* starting position */
/* (TTY uses this for flags if needed) */
vir_bytes address; /* data buffer address in (proc_nr) space */
/* (TTY uses it as ptr to info structure for ioctl */
} mess_devio;
typedef struct {
int m_source; /* who sent the message */
int m_type; /* what kind of message is it */
union {
mess_1 m_m1;
mess_2 m_m2;
mess_3 m_m3;
mess_4 m_m4;
mess_5 m_m5;
mess_6 m_m6;
mess_devio m_dio;
} m_u;
} message;
Jak jsme se již zmínili, probíhá přidělování času procesoru jednotlivým úlohám (timeslicing) na bázi prioritních úrovní a v případě uživatelských procesů preemptivně. V systému existují tři fronty (každá pro jednu prioritu), jež obsahují procesy, které jsou v daném okamžiku schopny běhu. Situace je znázorněna na obr. 2.1.
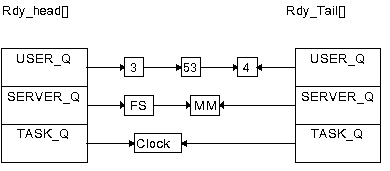
Obr.2.1.
Do nejvýše priorizované fronty se vkládají systémové tasky, do střední fronty servery (FS a MM) a v poslední jsou uživatelské úlohu. Začátky, resp. konce těchto front jsou uloženy v polích rdy_head[3] a rdy_tail[3] a prvky front jsou pospojovány prostřednictvím položky p_nextready záznamů tabulky procesů. Při výběru procesu, který má být naplánován, platí zásada, že je vybírán proces z čela nejvíce prioritní fronty. V rámci fronty jsou procesy zpracovávány jeden po druhém, tedy priorita jednotlivých procesů v rámci prioritní úrovně zůstává fixní. Pro jednoduchost tedy neuvažujeme změnu priority procesu během jeho života. Přeplánování procesu může nastat tehdy, kdy je k běhu připraven proces s vyšší prioritou, nebo uživatelský proces vyčerpal časové kvantum. K přeplánování dochází také tehdy, když se proces dobrovolně vzdá procesoru (wait(), pause()) nebo je mu odebrán při požadavku na zaslání/přijetí zprávy, který nemůže být splněn okamžitě. Jak jsme již naznačili, systémovým procesům (tasky, FS a MM) nemůže být procesor odebrán na základě vypršení časového kvanta. Je tomu tak proto, že předpokládáme správnost konstrukce systému, kde žádný z těchto procesů nemonopolizuje procesor na dobu delší než je nezbytně nutná pro uskutečnění požadované činnosti. U uživatelských procesů, které mohou být napsány kýmkoliv a jakkoliv, již tuto záruku nemáme.
Vhodná hodnota časového kvanta může být 100ms. Testy na existenci prioritnějšího procesu a vypršení časového kvanta se dějí v obslužné rutině časovače.
Tabulka procesů (process table) je pole záznamů obsahující informace o běžících procesech. Je určitou komplikací, že různé komponenty systému vyžadují vést o jednotlivých procesech velmi různorodá data. Abychom zamezili rozsáhlé výměně zpráv mezi komponenty při častých přístupech do společné tabulky (uvědomme si, že systém sestává z několika modulů a tabulka procesů může být součástí adresového prostoru jen jednoho z nich), je tabulka rozdělena do třech stejnolehlých tabulek příslušejících jádru, souborovému serveru a správci paměti. Pozice (index) záznamu určitého procesu je v rámci všech tří tabulek vždy stejná. Maximální počet současně běžících procesů je dán velikostí tabulky proc[] (konst. NR_PROCS).
Nyní se zaměříme na část tabulky procesů příslušející jádru, jejíž záznamy mají následující strukturu:
struct struct_proc {
reg_type p_reg[NR_REGS]; /* místo pro uložení registrů procesu */
int *p_sp; /* stack pointer */
struct pc_psw p_pcpsw; /* místo pro uložení PC(CS,IP) a PSW */
int p_flags; /* P_SLOT_FREE, SENDING, RECEIVING, NO_MAP ... */
struct mem_map p_map[NR_SEGS]; /* mapa paměti procesu */
int * p_splimit; /* nejnižší platná adresa ukazatele SP */
int p_pid; /* ID procesu (přiděluje MM) */
real_time user_time; /* spotřebovaný čas v uživatelském režimu (tiky) */
real_time sys_time; /* spotřebovaný čas v systémovém režimu */
real_time child_utime; /* kumulovaný uživatelský čas dětských procesů */
real_time child_stime; /* kumulovaný systémový čas dětských procesů */
real_time p_alarm; /* čas nejbližšího alarmu v ticích nebo 0 */
struct proc *p_callerq; /* začátek seznamu čekajících na odeslání zprávy */
struct proc *p_sendlink; /* další proces ve frontě čekajících na odeslání zprávy */
message *p_messbuf; /* ukazatel na buffer se zprávou */
int p_getfrom; /* od koho chce proces přijmout zprávu ? */
struct proc *p_nextready; /* další připravený proces v rámci prioritní fronty */
int p_pending; /* bitmapa signálů k doručení */
} proc[NR_TASKS+NR_SERVS+NR_PROCS]
Všimněme si v deklaraci pole konstant, které udávají jeho velikost. Konstanta NR_TASKS udává, kolik v systému existuje tasků, NR_SERVS je počet serverů. Konstanta NR_PROCS udává maximální počet uživatelských procesů, které mohou být zároveň spuštěny.
Procesy jsou v rámci systému jednoznačně identifikovány číslem pid (položka p_pid v struct_proc). Identifikace pozicí v rámci tabulky procesů nedostačuje vzhledem k tomu, že procesy mohou být dynamicky rušeny a jejich pozice znovu obsazovány procesy novými, avšak nový proces nesmí přijmout identitu procesu, který byl v příslušné pozici tabulky procesů před ním. Hodnoty pid přiděluje MM (nejjednodušeji postupně po řadě s návratem do nuly při přetečení. Pravděpodobnost, že při vzniku nového procesu stále ještě existuje proces, který byl vytvořen před 65536 žádostmi (u typu short int) o vytvoření procesu, je minimální. Přesto je však vhodné při generování nového pid tabulku procesů prozkoumat na duplicitu pid).
Krátkodobě, tj. pro účely systémových volání, jsou procesy z důvodu rychosti identifikovány pozicí v tabulce proc[].
Ne všechny pozice tabulky procesů jsou stále obsazeny. Obsazení položky proc[] (a stav procesu, který je s položkou svázán) lze vyčíst z položky p_flags. Při vytváření nového procesu hledáme od začátku tabulky položku, která nese v p_flags hodnotu P_SLOT_FREE. Pole p_flags rovněž může nabývat hodnot SENDING, resp. RECEIVING, které indikují, že je proces blokován a čeká na odeslání nebo přijetí zprávy. Jestliže není nastaven ani jeden z těchto příznaků, vykonává proces svůj vlastní kód. Poslední hodnotou, kterou může p_flags obsahovat je NO_MAP, která říká, že procesu dosud nebyla přidělena mapa paměti a není tedy ještě schopen běhu.
Pro zlepšení spravovatelnosti systému v mezních situacích zavádíme omezení na počet pozic, které mohou být maximálně obsazeny procesy obyčejných uživatelů. Jestliže počet obsazených pozic dosáhne hodnoty MAX_USERPROC, je vytváření dalších procesů povoleno pouze superuživateli. Tím zabráníme možnosti, že uživatelský proces mnohonásobným vytvářením procesů zahltí systém a ani superuživatel nebude mít možnost zlomyslný proces zlikvidovat, protože na spuštění procesů k tomu nezbytných nebude místo v tabulce procesů.
Během života proces prochází řadou stavů, které jsou indikovány hodnotou položky mp_flags tabulky mproc[], tedy té části tabulky procesů, která přísluší memory manageru. Stav je dán kombinací následujících příznaků:
WAITING: nastavuje se při volání wait(), probíhá čekání,
až skončí některý dětský proces
HANGING: (zombie) - nastavuje se při volání exit(),
platí do doby, než rodič zavolá wait()
PAUSED: nastavuje se při volání pause(), čeká se na (jakýkoli) signál
ALARM_ON: pomocný příznak indikující, že proces požádal
o doručení signálu SIGALRM
K přeplánování procesu dochází v několika situacích. Za prvé je to v případě vypršení časového kvanta, které je kontrolováno obslužnou rutinou přerušení časovače. Uživatelskému procesu i serveru může rovněž být odebráno řízení v obsluze kteréhokoli přerušení, jestliže byl v tomto přerušení naplánován některý task. Další možností je situace, kdy proces zaslal zprávu jinému procesu, ale ten ji nemůže přijmout, nebo naopak čeká na přijetí zprávy od jiného procesu. Obdobně je proces blokován v případě, že zaslal zprávu a čeká na odpověď, avšak tato odpověď mu bude moci být poskytnuta až později asynchronně (např. blokující I/O služby). Poslední důvod přeplánování nastává, když se proces dobrovolně vzdá procesoru před vypršením časového kvanta (systémová volání wait() a pause()).
Jelikož při přepínání procesu musíme zachovat hodnoty registrů, abychom je mohli při obnovování činnosti dané úlohy zrestaurovat, musíme zvolit vhodné místo pro jejich uložení. Jako výhodné se jeví uložení do slotu příslušejícího přerušenému procesu v tabulce procesů.
Jelikož se v různých rutinách systému často odkazujeme na aktuální proces, je výhodné udržovat ukazatel do tabulky procesů na proces, který právě běží. K tomu poslouží globální proměnná cur_proc. Taktéž udržujeme v proměnné bill_proc ukazatel na proces, kterému se právě účtuje spotřebovaný čas procesoru. Tato informace je potřebná k tomu, že např. při běhu file systému musíme být schopni čas, který spotřeboval, připočíst procesu, který file systém o příslušnou službu požádal. Podobně je tomu v případě běhu některého ovladače zařízení. Vždy při tiku hodin je třeba rozhodnout, kterému procesu spotřebovaný čas přičíst na vrub.
Již jsme se zmínili, že v době přerušení a při přepínání kontextu se uschovávají registry do slotu tabulky proc[] přerušeného procesu. Registry CS,IP a flags, udávající bod, odkud bude později přerušená úloha pokračovat, jsou uschovány na zásobníku příslušné úlohy.
Co se týče umísťování zásobníků jednotlivých procesů a tasků a přechodů mezi nimi při přeplánovávání, je zde patrný rozdíl mezi tasky a ostatními procesy. U uživatelských procesů a serverů je stack přidělen v adresovém prostoru příslušného procesu paměťovým manažérem, zatímco tasky používají stacky v datovém segmentu kernelu, jejichž adresy se naleznou v poli t_stack[]. Tasky totiž nemají přiděleny paměťové segmenty, jako je tomu u procesů (viz popis MM). Tato anomálie je způsobena tím, že MM je běžným procesem, který může běžet až tehdy, když se rozběhnou tasky. Ty tedy nemohou využívat jeho služeb.
U každého procesu je třeba evidovat, které jiné procesy čekají na okamžik, až náš proces od nich převezme zprávu. Takovéto procesy se vrší do fronty, na jejíž čelo ukazuje položka tabulky proc[] p_callerq. Pro spojování uzlů této fronty je určena položka p_sendlink. Propojení je realizováno nastavováním těchto pointrů přímo na záznamy tabulky procesů; dynamicky se žádná další paměť nealokuje (jako ostatně nikdy). Toto schema si můžeme dovolit, jelikož víme, že proces může být vždy členem nejvýše jedné fronty čekajících procesů. Je tomu tak proto, že poté, co proces předá žádost o zaslání zprávy jinému procesu a je zařazen do fronty čekajících, je až do doby doručení této zprávy zablokován.
V okamžiku, kdy proces žádá převzetí zprávy, zkoumá jádro příslušnou frontu procesů, které čekají na zaslání zprávy. Pokud je prázdná, proces se zablokuje. V opačném případě se ve frontě (od čela) hledá proces, od něhož je přijímající proces ochoten zprávu převzít, nebo se vezme první proces z čela fronty, pokud proces čeká na příjem zprávy od kohokoliv. V každém případě se proces, jehož zpráva byla úspěšně převzata, odstraní z fronty čekajících a odblokuje se.
V okamžiku, kdy dojde k zablokování procesu, je samozřejmě volán plánovač, aby přidělil procesor nejprioritnějšímu procesu, který je v dané chvíli schopen běhu.
Hardwarově závislou část obsluhy přerušení se snažíme minimalizovat a umístit do zvláštního modulu. Naším cílem je převést hardwarové přerušení na běžnou zprávu, která bude zaslána příslušnému tasku (nejspíše ovladači zařízení). Jediným rozdílem oproti komunikaci mezi procesy je skutečnost, že hardwarové zařízení nemůžeme zablokovat, jako bychom to udělali s vysílajícím procesem a tak jej donutit k tomu, aby počkalo, až přijímající proces ukončí právě rozpracovanou činnost. U většiny zařízení (zejména řadičů disků) však můžeme příchod přerušení předvídat, je totiž reakcí na některou námi explicitně spuštěnou akci.
Pokud tedy např. ovladač disků vyšle pokyn k nastavení hlavy, zablokuje se čekaje ne na zprávu od libovolného procesu, ale od hardware. Tím se zabezpečí, že nemůže nastat situace, že by v okamžiku příchodu přerušení od řadiče disků pracoval ovladač disků na něčem jiném a zprávu nemohl přijmout. Současně tím ani příliš nedegradujeme výkonnost systému, jelikož v době nastavování hlavy je ovladač diskového zařízení zablokován a čas může být přidělen jiným procesům.
Určitý problém nastává se zařízeními, které mohou generovat přerušení kdykoliv, což je zejména klávesnice a RTC obvod. To nám vadí proto, že potřeba reentrantnosti některých tasků, plynoucí ze zcela asynchronního generování přerušení se neshoduje s jinde aplikovaným mechanismem rendez-vous. Proto při zpracování těchto přerušení provádíme jen nejnutnější akce potřebné k zapamatování nastalé události a předání události ke zpracování příslušnému tasku provedeme později. Přerušení od časovače není kritické, jelikož je jeho obsluha poměrně snadná a navíc může být odloženo s tím, že se pouze počítá (proměnná lostTicks), kolik tiků nebylo obslouženo a později (při některém z dalších přerušení) je vše zkompenzováno. Nepříjemnou zůstává klávesnice a sériová linka, která může generovat i řadu následných přerušení obecně kdykoli. Zde je nutné uschovávat přijaté znaky ve zvláštních pomocných bufferech, než jsou předány ovladači.
Zpráva se tasku z rutiny přerušení nedoručuje voláním send() jako při komunikaci mezi ostatními moduly systému, ale voláním mini_send(), které volajícího nezablokuje v případě, že zprávu nelze okamžitě doručit, ale namísto toho vrátí chybový kód. V této situaci se informace o zprávě o přerušení, kterou se tasku nepodařilo doručit, uchovává ve zvláštním bitovém poli (busy_map), kde každý bit odpovídá jednomu typu podporovaného přerušení. Vždy na konci přerušovací rutiny tuto bitmapu prohledáváme a zkoušíme informaci o proběhlých a doposud nezpracovaných přerušeních příslušným taskům doručit. Zde si musíme uvědomit, že doručením zprávy zablokovaný task sice uvedeme do stavu „schopný běhu", nemusí však ihned nutně dojít k jeho naplánování (pokud právě běží jiný task).
Na konci obslužné rutiny přerušení se vždy testuje, zda nemá běžet proces s vyšší prioritou (vlivem naplánování tasku nebo serveru) nebo nedošlo-li k vypršení časového kvanta uživatelského procesu. Pokud ano, přeplánuje se.
Na závěr poznamenejme, že volání služeb jádra, která se realizují prostřednictvím INT31h, rovněž procházejí přes obslužnou rutinu přerušení.
Správa paměti v TUOXu vychází z možností reálného režimu mikroprocesoru 8086, takže nepředpokládá implementaci virtuální paměti (paging) ani swapperu procesů, pro které zde chybí hardwarová podpora.
Veškerá paměť, která se v systému alokuje, je zarovnána na paragrafy (16B). Z toho plyne, že pro adresaci začátku bloku vystačíme s jedním slovem (16-bitů). Ze stejného důvodu zavedeme omezení pro délky přidělovaných oblastí - musí být vždy násobkem 16. Tím jednak dosáhneme významné úspory místa zabraného systémovými tabulkami a navíc si usnadníme implementaci na segmentované architektuře 8086.
V dalším textu se budeme také setkávat s pojmem virtuální adresa. V našem kontextu tím budeme rozumět adresu v rámci adresového prostoru určitého procesu. Na adresu fyzickou může být přepočítána tak, že v systémových tabulkách najdeme fyzickou adresu příslušné oblasti (kód,data+stack) a virtuální adresu k ní jednoduše přičteme. Fyzickou adresu chápeme jako lineární; její přepočet na tvar segment:offset specifický pro procesory 80x86 izolujeme do univerzální, v celém systému používané rutiny pro kopírování úseků paměti mezi fyzickými adresami, která je napsána v assembleru.
Podobně jako UNIX implementuje TUOX architekturu segmentů (název nijak nesouvisí se segmenty 8086), kde každému procesu jsou přiděleny dva (resp. tři) segmenty. Pod pojmem segment si představujme souvislou paměťovou oblast. Jedním z nich je segment kódový (T), zatímco data a zásobník jsou ve společném datovém prostoru. Zásobník roste shora dolů (od vyšších adres k nižším), inicializovaná a neinicializovaná (BSS) data jsou uložena na nižších adresách, mezi nimi je nevyužitý prostor (GAP). Název nevyužitý prostor nás však nesmí zavádět k úvaze, že je tato paměť z hlediska paměťového manažéru neobsazena. Naopak, je součástí paměti přidělené procesu a pouze ten svým chováním stanoví, jak s ní bude naloženo. Velikost textové oblasti plyne z délky kódu, zatímco velikost oblasti datové je určena v hlavičce spustitelného souboru. Vzhledem ke snadnosti implementace se omezíme na maximální velikost obou oblastí 2*64kB. S přihlédnutím k architektuře 80x86 pak můžeme i snadno řešit virtuální adresaci: adresy budou prostě NEAR pointry vztažené k hodnotě vhodně naplněného segmentového registru (jak jsme zvyklí z modelu SMALL). Příklad obsazení paměti procesem a jemu odpovídající hodnoty mapy paměti (mproc[].mp_seg[]) procesu můžeme najít na obr.3.1.
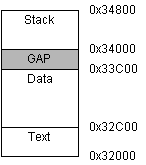
| . |
Virtual |
Physical |
Length |
| Text | 0 | 0x32000 | 0xC0 |
| Data | 0 | 0x32C00 | 0x100 |
| Stack | 0x140 | 0x32000 | 0x80 |
Obr.3.1.
Se znalostí virtuální adresy a prostoru, do kterého patří, tedy můžeme snadno rozhodnout, zda je paměťové místo jeho součástí. Je výhodné napsat v celém jádru využívanou funkci (umap()) , která vrátí fyzickou adresu na základě virtuální adresy, identifikace procesu a prostoru, do kterého virtuální adresa patří. Samozřejmě tato funkce rovněž ověřuje, zda je uvedená virt. adresa regulérní součástí zadaného adresového prostoru. (Tato funkce je implementována v rámci zdrojového kódu SYSTEM tasku).
Jak jsme si již řekli, vlastní MM svou část tabulky procesů, která obsahuje
jednak údaje o paměti přidělené jednotlivým procesům a jednak informace
nutné pro služby, které jsou k MM připojeny.
#define NR_SEGS 3 /* # segments per process */
#define T 0 /* proc[i].mem_map[T] is for text */
#define D 1 /* proc[i].mem_map[D] is for data */
#define S 2 /* proc[i].mem_map[S] is for stack */
EXTERN struct mproc {
struct mem_map mp_seg[NR_SEGS]; /* points to text, data, stack */
char mp_exitstatus; /* storage for status when process exits */
char mp_sigstatus; /* signal # which caused process to exit*/
pid_t mp_pid; /* process id */
pid_t mp_procgrp; /* pid of process group (used for signals) */
pid_t mp_wpid; /* pid this process is waiting for (one of variations of wait() )*/
int mp_parent; /* index of parent process */
/* Real and effective uids and gids. */
uid_t mp_realuid; /* process' real uid */
uid_t mp_effuid; /* process' effective uid */
gid_t mp_realgid; /* process' real gid */
gid_t mp_effgid; /* process' effective gid */
/* Signal handling information. */
sigset_t mp_ignore; /* 1 means ignore the signal, 0 means don't */
sigset_t mp_catch; /* 1 means catch the signal, 0 means don't */
sighandler_t mp_func; /* all signals vectored to a single user fcn */
unsigned mp_flags; /* flag bits */
} mproc[NR_PROCS];
/* Flag values */
#define IN_USE 001 /* set when 'mproc' slot in use */
#define WAITING 002 /* set by WAIT system call */
#define HANGING 004 /* set by EXIT system call */
#define PAUSED 010 /* set by PAUSE system call */
#define ALARM_ON 020 /* set when SIGALRM timer started */
Jak je patrné z definice struct_mproc, obsahují její členy nejen informace o uložení procesu v paměti, ale také o signálech a skutečných i efektivních identifikacích uživatele a skupiny, jimž proces patří.
Mechanismus evidence volné paměti je velmi přímočarý. Paměťový manažér (MM) si vede seznam volných bloků tříděný podle počáteční adresy. Seznam z počátku obsahuje jediný blok přes celou paměť, která zbyla volná po zavedení obrazu systému (+ příp. vyhrazená oblast na ramdisk). Při požadavku na přidělení paměti MM vyhledává od nejnižších adres první blok dostatečné délky (případně může optimalizovat s ohledem na minimální fragmentaci). Naopak při vracení paměti je vracený blok zařazen na příslušné místo seznamu a případně spojen s přilehlými bloky, pokud s nimi přímo sousedí. Záznamy popisující fragmenty volné paměti mají následující strukturu:
struct mem_map {
vir_clicks mem_vir; /* virtual address: pro data a kód 0, pro stack hodnota */
/* od začátku oblasti */
phys_clicks mem_phys; /* physical address */
vir_clicks mem_len; /* length */
};
MM taktéž implementuje řadu systémových služeb souvisejících se správou paměti a tvorbou procesů a poskytuje je uživatelským procesům. Jedná se o služby
Dále jsou v MM implementovány i další služby, které sice nesouvisí se správou paměti, avšak je zbytečné pro ně vytvářet další server proces (FS je sám o sobě dost rozlehlý, proto byly tyto služby připojeny k MM). Jedná se o implementaci systémových volání
Z hlediska uživatelských programů se tato volání realizují zavoláním příslušné funkce z knihovny, která zajistí zformulování zprávy a její předání memory manageru. Proces pak vyčká ve stavu zablokování do doby, než MM na zprávu odpoví a může být vráceno řízení z knihovní funkce.
Výčet akcí, které implementace jednotlivých volnání musí provádět, je možné najít v pseudokódu memory manageru.
Se správou paměti souvisí také způsob, kterým procesy čekají na dokončení dětských procesů a přebírají jejich návratový kód. Platí, že proces, který (dobrovolně či násilně) skončil, není uvolněn z paměti do té doby, než jeho rodič převezme návratový kód systémovým voláním wait(). V tomto mezidobí se dětský proces nachází ve stavu HANGING (v terminologii UNIXu „zombie"). Při přechodu procesu do stavu zombie se proces musí vyloučit z plánování a vypnout případné požadavky na doručení signálu SIGALRM. Paměť přidělená procesu by se mohla uvolnit ihned a ponechat neuvolněnu pouze pozici v tabulce procesů, v první implementaci to však není nezbytné a lze obé uvolňovat až rodičovský proces zavolá wait(). Návratový kód ukončeného procesu však lze každopádně nalézt v položce mp_existstatus tabulky mproc[].
Jak již bylo rozebráno, v situaci, kdy rodič skončí dříve než potomek, přebírá rodičovství potomka Init. Při voláních vedoucích k ukončení procesu tedy musí MM projít mproc[] aby zjistil, zda má proces potomky a pokud ano, nastavit jako jejich rodiče Init.
Po zavedení obrazu systému je nutné inicializovat tabulky MM tak, aby pokryly zbývající volnou paměť. Mapa paměti po zavedení systému je uvedena na obr. 3.2. Informace o začátku volné paměti je zavaděčem předávána do inicializační funkce memory manageru.
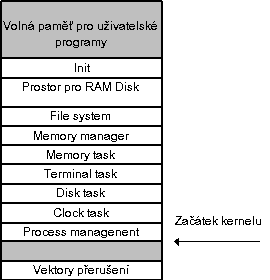
Obr. 3.2.
Signály pro proces mohou být generovány jak z mnoha vnitřních rutin operačního systému (signály SIGQUIT, SIGALARM, SIGINT), tak z jiných uživatelských procesů voláním kill(). Signály mohou být doručovány konkrétnímu procesu nebo skupině procesů. Pokud je původcem signálu uživatelský proces, lze signalizovat zásadně vždy jen mezi procesy se stejným UID a spuštěnými ze stejného terminálu.
V případě, že má být procesu zaslán signál, nastaví jádro v bitové mapě p_pending záznamu proc[] bit přiřazený tomuto signálu. Ve vhodné chvíli se pak periodicky zjišťuje, jsou-li pro některý proces zaregistrovány (pending) nějaké signály a pokud ano, požádá se o jejich doručení procesu MM.
Každý proces může určit, které ze signálů mají být doručovány do jeho obslužných rutin, které mají být ignorovány a které se mají zpracovávat ve standardních systémových obslužných rutinách. Hodnoty jednotlivých bitů položky sig_catch mproc[] určují, které ze signálů hodlá proces obsluhovat, podobně bity položky sig_ignore definují signály, jež mají být ignorovány. V případě, že se vyskytne signál, který proces neodchytává ani neignoruje, proces se násilně ukončí (kill + případný core dump).
Způsob obsluhy signálů odpovídá jejich asynchronnímu charakteru. Na zásobník se nachystají data jako při přerušení a číslo signálu. MM poté zajistí volání uživatelské funkce obsluhy signálů, která je součástí knihoven příslušného procesu (MM má pointer na tuto funkci, byl mu předán při spuštění programu (nebo při prvním volání signal()) ). Na konkrétní obslužný handler se řízení předává až zevnitř knihoven.
Na závěr ještě poznamenejme, že doručuje-li se procesu signál v době, kdy tento proces čeká zablokovaný po volání read(), volání read() se po obsluze signálu přeruší a vrátí řízení volajícímu s chybovým kódem EINTR.
Se spouštěním programů souvisejí volání exec() a fork(), které MM implementuje. Podobně jako v UNIXu dochází nejprve k vytvoření nového (identického) procesu rozštěpením rodiče voláním fork(). Poté se může voláním exec() vyměnit obraz procesu za kód načtený ze zadaného souboru.
Z hlediska programů je přístup k volání exec() realizován pomocí knihovní funkce execv(int argc, char* argv[], char* environment[]). Jelikož se předpokládá, že program začne voláním funkce main, která na zásobníku očekává parametry argc, argv[] a environment[], je nezbytné zásobník do takovéhoto úvodního tvaru zkonstruovat. Do adresního prostoru procesu musíme samozřejmě předat nejen tato pole pointrů, ale i samotné (řetězcové) hodnoty prvků těchto polí.
Všechny uvedené informace jsou procesu předávány na zásobníku. Prvotní konstrukci zásobníku provede podle předaných parametrů knihovní funkce execv(). Poté zašle MM zprávu EXEC a jako parametr zprávy předá odkaz na paměťovou oblast, kde MM zásobník určený pro proces najde. MM nyní provede relokaci pointrů na předaném zásobníku s ohledem na skutečnou hodnotu stack pointru v cílovém procesu a přesune jej do jeho adresového prostoru. Relokace je nutná proto, že knihovní funkce execv() při konstruování zásobníku neví nic o tom, na kterých adresách bude výsledně zásobník procesu uložen. Počíná si tedy tak, jako by jeho vrchol byl na adrese 0. Zásobník předávaný mezi knihovní funkcí execv() a MM tedy obsahuje tyto informace (odspoda nahoru):
V uvedeném stavu nalezne zásobník obsluha zprávy EXEC memory manageru. Ta zásobník projde a připojí na jeho vrchol ještě tři parametry, jak je očekává main: argc, argv a environment. Poté zavolá main(), která již byla překladačem vygenerována jako běžmá funkce a jako taková přebírá své parametry standardním způsobem ze zásobníku.
Jak vidíme, environment procesu je uložen na zásobníku a protože nemá kam růst, nemůže tam být přímo modifikován. Ve skutečnosti procesy v TUOXu ani nemají důvod, proč svůj vlastní environment modifikovat. Ukazatel na oblast environmentu získá proces jako parametr funkce main(). Při štěpení procesu se dědí celá image, tedy i environment. Jestliže dětský proces hodlá poté nahradit svůj kód kódem jiného programu (voláním exec()), předává se jako jeden z parametrů ukazatel na prostředí. Toto prostředí však může být zkonstruováno kdekoli v datovém prostoru volajícího procesu. Tak například uvažujeme-li shell, který umožňuje dynamicky proměnné environmentu nastavovat, vypadala by situace takto:
Program Shell získá ukazatel na prostředí z programu login, který po přihlášení vyměnil ve stejném procesu svůj kód za kód Shellu. (login získal prostředí od Initu při fork() a následném exec()). Shell nyní může read-only environment ze zásobníku překopírovat do své vnitřní tabulky a tam jej podle pokynů uživatele modifikovat ve vlastní režii jak je mu libo. Jestliže poté uživatel instruuje shell k vyvolání externího příkazu, použije při volání exec() ne pointer na prostředí, který shell obdržel do své funkce main(), ale ukazatel na vnitřní tabulku proměnných prostředí, spravovanou shellem.
Pro každou třídu zařízení existuje v TUOXu zvláštní task. Pokud to má smysl, je každý task napsán tak, že je schopen podporovat i více zařízení stejné třídy (např. řadič floppy). Jelikož veškerý vstup a výstup v TUOXu je koncepčně napojen na file system, komunikují tasky především s modulem FS, ale také mezi sebou. Komunikace probíhá standardně, tj. pomocí výměny zpráv. Připomeňme, že ač jsou tasky fyzicky slinkovány do společného adresového prostoru, zůstávají logicky odděleny.
Obecná struktura všech tasků je vždy shodná. Každý task má inicializační část, který proběhne jedenkrát po zavedení systému a hlavní smyčku, ve které vždy čeká zablokován na příjem zprávy, po jejím příchodu předá zprávu ke zpracování příslušné rutině, po návratu z ní zašle odpověď a čeká na další požadavek. Tím se automaticky řeší serializace požadavků na přístup k zařízení od jednotlivých konkurujících si procesů.
Stejně jako v UNIXu rozlišujeme zařízení bloková a znaková podle toho, zda nejmenší jednotkou přenosu dat je znak, či celý blok.
Zvláštní postavení má tzv. system task, který sice nemá co dělat s obsluhou žádného zařízení, ale integruje řadu nízkoúrovňových funkcí, které musí být realizovány na úrovni jádra a zpřístupněny FS a MM. Tvoří tedy jakési okno MM a FS do jádra, které by tam jinak neměly žádný přístup.
Podívejme se nejprve na bloková zařízení (RAM Disk, Floppy driver, ...). Formát zprávy předávající požadavky ovladačům blokových zařízení je společný. Obsahuje vždy tyto položky: operation,minor_dev_nr,position, requesting_process, addr, count. Je jasné, že operation určuje požadovanou operaci, minor_dev_nr číslo zařízení (pro rozlišení, je-li jich více stejného typu), pozice určuje pozici požadovaného bloku v rámci zařízení, adresa je adresa paměti, odkud/kam budou data přenášena. Count je požadovaný počet bajtů. Odpovědí na každou takovou zprávu je počet úspěšně přenesených bajtů.
Jediným znakovým zařízením, které v současné době systém podporuje, je terminál (klávesnice).
Ovladač hodin jednak udržuje systémový čas (v podobě boot time a počtu tiků od bootu) a jednak sleduje situace, které mají na reálném čase závislost. Jsou jimi přednastavené alarmy, ale také systémové události jako vypršení časového kvanta nebo okamžik vypnutí motoru floppy mechaniky. Významnou úlohou clock driveru je rovněž sledování času spotřebovaného procesorem ve prospěch jednotlivých procesů. Clock driver zná tyto zprávy: SET_TIME, GET_TIME, SET_ALARM a CLOCK_TICK. Poslední jmenovaná zpráva je zasílána obslužnou rutinou přerušení vždy při tiku hodin. V inicializační části ovladač nastaví systémové hodiny (8253) na frekvenci 60 Hz.
Clock task obhospodařuje následující proměnné:Zprávy SET_TIME a GET_TIME jsou triviální. Parametrem zprávy ALARM je časový interval, po kterém má být odesílatel zprávy informován. Jestliže alarm požadoval proces, poznačí se čas alarmu do jeho slotu tabulky procesů a v patřičném okamžiku se mu signalizuje signálem SIGALRM. Naopak u tasků je přídavným parametrem zprávy SET_ALARM adresa rutiny, která má být v příslušném okamžiku vyvolána. Tuto adresu si clock driver poznačí do pole watch_dog[], v němž má každý z tasků vyhrazenu jednu pozici. Každý proces, resp. task, tedy může najednou registrovat nejvýše jeden alarm.
File system i memory manager běží v oddělených adresních prostorech. Přesto je však nutné zabezpečit, aby tyto procesy měly přístup do tabulek jádra. Z tohoto důvodu byl do systému zařazen tzv. system task, který na základě požadavků FS a MM ve formě zpráv přístup uskutečňuje. System task rozumí zprávám, jejichž názvy, parametry a vysvětlení jsou uvedeny v tab. 4.1.
| Zpráva | Iniciátor | Parametry | Popis |
| SYS_FORK | MM | sloty tabulky procesů child a parent procesů | Použito při štěpení procesu. Do slotu tabulky příslušející novému procesu se zkopírují informace ze slotu rodičovského procesu |
| SYS_NEWMAP | MM | slot, popis přidělených oblastí paměti | Zasílá se při fork, exec a brk, MM tím informuje kernel o oblastech paměti, které novému procesu přidělil. Informace se ukládají do položek p_map a p_reg tabulky procesů |
| SYS_EXEC | MM | . | Používáno při exec, MM před tím připravá stack nového programu (argumenty a enviroment pro main). System task nastaví SP, zruší případné alarmy. Nový proces se odblokuje, ale na zprávu se neodpovídá (není komu, image byla vyměněna) |
| SYS_XIT | MM | . | Zasílá se při ukončování procesu (volání exit, ukončení sígnálem). Pokud proces čekal na příjem/vyslání zprávy, musí se odstranit se všech front |
| SYS_GETSP | MM | . | Vrací hodnotu SP, tu je nutno znát pro volání brk(), sbrk() |
| SYS_TIMES | FS | . | Vrací časy (systémový a uživatelský) spotřebovaný zadaným procesem |
| SYS_SIG | . | . | Příprava k vyvolání obsluhy signálu. Uloží PSW,CS,IP a čísla signálu na zásobník procesu, dekrement SP |
| SYS_COPY | . | . | Zprostředkování kopie paměťové oblasti mezi FS,MM a uživatelskými procesy |
Tab. 4.1
Díky rendez-vous architektuře komunikace procesů máme automaticky zajištěnu serializaci požadavků na zařízení. Ovladač floppy je realizuje postupně, nepoužívá žádnou formu „výtahového algoritmu". Ovladač poskytuje funkce přečtení a zápis bloku a funkci ioctl(), navenek prezentované jako obsluhované zprávy. Podle jednotlivých podporovaných formátů disket probíhá přepočet logického čísla bloku na fyzickou adresu sektoru.
Formátování disket není nutné řešit, provede se mimo systém (např. z MS-DOSu). Počty stop a sektorů na stopě jsou převzaty z obvyklých standardů používaných v MS-DOS. Postačí podporovat diskety 3,5'' 1.44 MB a případně 5,25'' 1.2 MB.
Ovladač floppy disku komunikuje přímo s řadičem FD (komp. s I8272) a řadičem DMA (I8237).
Dále diskutovaný modul poskytuje možnost dívat se na paměť (resp. její vymezenou oblast) jako na blokové zařízení. To nám poslouží především pro implementaci RAM disku, jehož použití značně urychlí přístup k souborům.
RAM disk se z pohledu FS jeví jako běžné blokové zařízení a jelikož máme k dispozici koncepci montování svazků souborového systému, nepřináší nám jeho implementace žádné zvláštní obtíže. Je na uvážení, zda systém nepostavit tak, že proces Init RAM disk přimontuje pod root načtený z diskety s ROOT File System a neprohlásí je za svůj kořenový adresář a tím i za kořenový adresář svých potomků.
Ovladač RAM disku je napojen na čtyři speciální soubory. Je to jednak /dev/ram, jímž se zpřístupňují bloky samotného RAM disku, ale též soubory /dev/mem a /dev/kmem, které po blocích zpřístupňují celou paměť systému, resp. oblast příslušející kernelu. Pochopitelně k posledně dvou jmenovaným souborům má právo přístupu pouze root, jelikož jimi získáváme neomezenýáme přístup do kterékoli oblasti paměti. Jejich existence je však výhodná zajména pro účely ladění. Začátky a délky jednotlivých paměťovych oblastí se nastaví zvnějšku zprávou DISK_IOCTL.
Posledním souborem, který je na ovladač RAM disku napojen, je /dev/null. Data zapisována do tohoto souboru jsou zahazována, při čtení z něj je zásadně vracen nulový počet načtených bajtů.
Mimo již zmíněné zprávy DISK_IOCTL podporuje ovladač zprávy DISK_READ a DISK_WRITE pro přečtení, resp zápis bloku, jejichž formát je stejný jako u ostatních blokových zařízení.
Ovladač terminálu je typickým představitelem třídy znakových zařízení. Ačkoli v současné verzi podporuje TUOX pouze klávesnici, je ovladač terminálu napsán tak, aby jej bylo možné snadno rozšířit o obsluhu obecně libovolného počtu terminálů komunikujících přes RS232. Klávesnice je pro nás mírně nepříjemná z toho hlediska, že komunikace s ní probíhá dosti odlišně než s obvyklým terminálem připojeným přes sériovou linku. Klávesnice také neposílá ASCII hodnoty znaků, jako to dělají terminály, ale scan kódy, které musí být na ASCII převedeny ovladačem. Mimo to musíme ještě zohlednit, že klávesnice generuje přerušení vždy dvakrát od jednoho znaku - při stisku a puštění klávesy. Ovladač se nám tedy rozpadne na část společnou pro všechny možné terminály a na část hardwarově závislou.
Podobně jako v UNIXU může každý z terminálů pracovat v jednom ze tří (nastavitelných) režimů, nazývaných terminálová (nebo linková) disciplína:
COOKED - znaky jsou procesu doručovány až po odřádkování, je umožněna editace na úrovni ovladače terminálu
CBREAK - každý znak je procesu předán okamžitě; je podporováno generování signálů
RAW - kódy znaků se bez další transformace předávají procesu, tj. řídící
znaky se neinterpretují
Stavy a softwarové nastavení jednotlivých terminálů připojených k systému nalezneme v záznamech pole tty_struct[] (definice záznamu tty/tty.h). V pozdější implementaci obsahující RS232 terminály zde budou uloženy i komunikační parametry. Stav terminálu např. udává, zda je pozastaven výpis, softwarové nastavení zahrnuje takové informace jako znaky použité pro generování signálů SIGINT,SIGQUIT, pozastavení a obnovení výpisu apod. Záznam tty_struct[] také obsahuje vstupní a výstupní fronty jednotlivých terminálů.
Ovladač musí implementovat následující funkce: přečtení a zápis znaků
z/na terminál, zrušení předchozího požadavku na převzetí znaku, funkci
ioctl() pro nastavení charakteristik jednotlivých terminálů a konečně obslužnou
rutinu přerušení pro převzetí znaku ze zařízení. Tab. 4.2 shrnuje těmto
činnostem odpovídající zprávy a přiřazuje význam jejich parametrům:
| m_type | TTY_LINE | PROC_NR | COUNT | TTY_SPEK | TTY_FLAGS | ADDRESS |
| TTY_CHAR_INT | . | . | . | . | . | . |
| TTY_READ | minor dev | proc_nr | count | . | O_NONBLOCK | buf_ptr |
| TTY_WRITE | minor dev | proc_nr | count | . | . | buf_ptr |
| TTY_IOCTL | minor dev | proc_nr | func_code | params | flags | . |
| TTY_CANCEL | minor dev | proc_nr | . | . | . | . |
Tab. 4.2
Parametry posledního volání, týkajícího se určitého terminálu, jsou
uchovány v položkách příslušného záznamu tty_struct[]. To nám plně postačuje,
jelikož v jediném okamžiku může být s terminálem svázán pouze jeden proces
na popředí a ten je do doby vyřízení svého požadavku zablokován, takže
se nevyřízené požadavky nemohou hromadit.
Pro získání lepší představy jak komunikace uživatel-proces prostřednictvím terminálu probíhá, si nyní vysvětlíme typický scénář. Budeme uvažovat terminál v podobě klávesnice IBM-PC.
Po zavedení systému přečte Init (uměle vytvořený proces, který je (pra)předkem všech postupně vynikajících procesů) soubor /etc/ttys, který definuje terminály, se kterými má systém pracovat. Pak se rozštěpí a v každé kopii nahradí svůj kód programem login s tím, že vstup, výstup i chybový výstup přesměruje na soubor odpovídajícího terminálu (/dev/tty0 - ttyN). Je starostí souborového systému, aby při požadavku o přístup k souboru standardního vstupu, resp. výstupu rozpoznal, že se jedná o speciální soubor reprezentující zařízení a žádost odeslal jeho ovladači.
Stiskne-li nyní uživatel klávesu, generuje se přerušení. V jeho obsluze se zavolá rutina keyboard() z hardwarově závislé části ovladače terminálu, ve které se z klávesnice přečte scan code a uloží do pomocné fronty tty_driver_buf[]. Pozor, nejedná se o frontu totožnou se vstupní frontou žádného terminálu, ale o univerzální vyrovnávací buffer, ve kterém se znaky ode všech terminálů uchovávají do té doby, než je bude terminálový task schopen převzít a uložit do příslušné vstupní fronty. Protože jsou zde promíseny znaky ode všech terminálů, uchovávají prvky fronty nejen samotné znaky, ale i informaci o čísle (fyzického) terminálu, ze kterého znak přišel.
V případě klávesnice se navíc znak ukládá do tty_driver_buf[] pouze tehdy, když šlo o stisk klávesy.
Po zařazení znaku do tty_driver_buf[] se obsluha přerušení (keyboard()) pokusí voláním k_interrupt() doručit terminálovému tasku zprávu TTY_CHAR_INT. Selže-li tento pokus (znaky přicházejí příliš rychle a terminálový task je zaneprázdněn), znak zůstane uchován ve frontě, nastaví se příslušný bit v busy_map a terminálovému tasku se zpráva doručí při některém dalším přerušení (z jakéhokoli zdroje).
V okamžiku, kdy terminálový task přijme zprávu o přijetí znaku, převezme tento znak (resp. více nakumulovaných znaků) z vyrovnávací fronty a uloží je do příslušné vstupní fronty. Zde je nutné dát pozor na to, že i v době zpracovávání znaků z tty_driver_buf[] může přijít další znak, který nesmíme ztratit tím, že počet prvků ve frontě (určený prvním bajtem pole) v dobré víře, avšak v nevhodné chvíli, vynulujeme. Kdykoli nám totiž může na pozadí přijít další znak. Proto si před zpracováním znaků tty_driver_buf[] nejprve uděláme kopii této fronty při zakázaném přerušení, vynulujeme počet prvků v originálu a až poté přerušení opět povolíme. Při přenášení znaků do vstupní fronty v případě klávesnice také převádíme scan kód na odpovídající ASCII hodnotu. K tomu potřebujeme znát stav modifikačních kláves (SHIFT,CTRL,CAPS LOCK...), který udržuje HW závislá část driveru v globální proměnné.
Pokud je terminál v cooked módu a znak je editační klávesou, provedou se ve vstupní frontě příslušné úpravy. Vždy při příchodu znaku se testuje, zda je nějaký proces zablokován čekáním na vstup z daného terminálu (to poznáme z položky tty_incaller tty_struct[]). Pokud tomu tak je a nashromaždilo se dostatečné množství znaků (opět to poznáme z položky tty_inleft), aby bylo možné požadavek procesu uspokojit (tj. jeden znak v módech RAW a CBREAK a celý řádek v módu COOKED), nakopírují ze data do adresového prostoru žádajícího procesu (tty_struct[].tty_inproc) a zašle se zpráva REVIVE procesu tty_struct[].tty_incaller, který vstup z terminálu zprostředkoval (prakticky vzato, je to vždy FS a jen ten umí na zprávu REVIVE reagovat).
FS v reakci na zprávu REVIVE zjistí, zda jsou některé procesy zablokovány ve stavu čekání na vstup z daného terminálu a pokud ano, vstup se jim předá (tj. nakopíruje do jejich adresového prostoru) a příslušné procesy se odblokují. Proces může najednou převzít nejvýše jeden vstupní řádek.
Při zpracování došlého znaku musíme také rozhodnout, zda je zapnuto echo a je-li znak tisknutelný, Pokud ano, voláním echo() přidáme znak do výstupní fronty a zajistíme okamžitý výpis této fronty na výstupní zařízení.
Ovladač terminálů rovněž musí sledovat řídící znaky pro pozastavení
a obnovení výpisu (a vést si aktuální hodnotu tohoto nastavení) a zajistit
generování některých signálů jako reakci na příslušné klávesy (Ctrl+C,DEL).
V důsledku vede pozastavení výpisu k zablokování vypisujícího procesu v
okamžiku, kdy se pokusí zapsat na terminál další data. Pozastavení výpisu
poznáme podle nastavení položky tty_inhibited=STOPPED, které je mj. testováno
v rutinách realizujících fyzický výstup znaku na zařízení. Detekce znaků
pro pozastevení/obnovení výpisu se děje přímo v obsluze přerušení, zatímco
žádost o zaslání signálu řeší až terminálový driver v obsluze TTY_CHAR_INT.
Tolik co se týče vstupu znaků. Výstup je trochu jednodušší. Proces hodlající zapisovat znaky na terminál volá knihovní funkci printf(), která řetězec zformátuje a předá volání jádra write(). V něm se zformuje zpráva pro FS, který již požadavek přesměruje na ovladač příslušného terminálu a zašle mu zprávu TTY_WRITE. Obslužná rutina této zprávy (do_write()) přebírá ukazatel na vypisované znaky a jejich počet. Tyto hodnoty spolu s identifikací volajícího procesu uloží do příslušné položek tty_outproc,.. tty_struct[]. Z do_write() se pak již volá rutina, která provede fyzický zápis na výstupní zařízení. Ukazatel na tuto rutinu najdeme v položce tty_devstart() záznamu tty_struct[]. V případě monitoru jde o rutinu console(). Ta obsahuje smyčku, která postupně načítá znaky určené pro výstup (z adresového prostoru uživatelského procesu) a pro každý z nich volá out_char(). Zde se zpracovávají speciální znaky (pohyb kurzoru, bell...) a ostatní se akumulují ve výstupní frontě tty_outqueue (spolu se svými atributy). Se samotným přenesením znaků z této fronty se čeká na vertical retrace, resp. na připravenost protistrany u terminálů RS232..
Pokud se výstupní fronta naplní nebo se zpracovává znak, který mění
pozici kurzoru (vč. CR,LF), je nutné přenesení znaků do video RAM vyřídit
okamžitě. To se uskuteční voláním funkce flush(), která s použitím assemblerovské
funkce vid_copy() počká na retrace a znaky do video RAM nakopíruje.
Ovladač musí být rovněž schopen zpracovat ESC sekvence, čímž umožníme programům jako jsou textové editory pružnější zacházení s obrazovkou. Minimálně budeme podporovat sekvence moveto, set_attr, clrscr a scroll (scrolling budeme řešit patrně softwarově pouhým přesunem bloku ve video RAM). Všechny ESC sekvence mají délku tři bajty a jsou shrnuty v tab.4.3:
| bajt 1 | bajt 2 | bajt 3 | Význam |
| ESC | n1 | n2 | posun kurzoru na pozici (n1,n2) |
| ESC | ~ | 0 | výmaz obrazovky od kurzoru ke konci |
| ESC | ~ | 1 | scroll o jeden řádek |
| ESC | z | n1 | nastavení atributu na n1 |
Tab. 4.3
Aktuální pozice kurzoru je udržována v položkách tty_row a tty_column záznamu tty_struct[] (poznamenejme, že souřadná soustava je orientována tak, že počátek je v levém dolním rohu a souřadnice x a y rostou doprava a nahoru). Při výskytu znaku LF na posledním řádku musíme vyvolat scroll. Podobně předtím, než zareagujeme na sekvenci moveto, musíme zajistit vyprázdnění fronty, aby se případné akumulované znaky vypsaly ještě na starou pozici.
Z hardwarově závislých částí ovladače TTY je v úvodní fázi implementována pouze obsluha klávesnice, realizovaná pomocí funkce keyboard(), volané přímo z jádra při reakci na přerušení 9 a ovladač RS232, obsluhující přerušení sériového portu (INT 0Ch, resp. 0Bh)
Souborový systém (FS) zabezpečuje přístup k souborům a zařízením (blokovým i znakovým). Z hlediska uživatelských procesů je pak přístup ke oběma těmto typům prostředků unifikován a vše se jeví jako soubor. Na soubory (a tím i na zařízení) je aplikován mechanismus přístupových práv, který známe z UNIXu (práva RWX pro uživatele, jeho skupinu a ostatní, setuid bit).
FS rozumí dále uvedené skupině zpráv, které v podstatě přímo odpovídají systémovým voláním:
Parametry jednotlivých zpráv jsou přehledně shrnuty v tab. 5.1.
| Zpráva | Parametry | Odpověď |
| ACCESS | jméno souboru, access mode | status |
| CHDIR | jméno nového prac. adresáře | status |
| CHMOD | jméno souboru, mód | status |
| CHOWN | jméno souboru, UID, GID | status |
| CHROOT | jméno nového root adresáře | status |
| CLOSE | fd | status |
| CREAT | jméno souboru, mód | fd |
| DUP | fd (pro DUP2 dva deskriptory) | fd |
| FSTAT | fd, buffer | status |
| IOCTL | fd, čislo funkce, argument | status |
| LINK | jméno souboru, jméno linku | status |
| LSEEK | fd, offset, odkud | nová pozice |
| MKNOD | jméno spec. souboru, mode, major & minor device number | status |
| MOUNT | spec. soubor, adresář kam namontovat, R_ONLY flag | status |
| OPEN | jméno souboru, r/w flag | fd |
| PIPE | . | fd[2] |
| READ | fd, buffer. počet bajtů | počet načtených bajtů |
| STAT | jméno souboru, status buffer | status |
| STIME | nový platný čas | status |
| SYNC | . | vždy OK |
| TIME | . | aktuální čas |
| TIMES | buffer pro uložení uživatelských a systémových časů spotřebovaných procesem a dětskými procesy | vždy OK |
| UMASK | komplement masky módu | původní maska |
| UMOUNT | jméno speciálního souboru | status |
| UNLINK | jméno souboru | status |
| UTIME | jméno souboru, časy | vždy OK |
| WRITE | fd, buffer, počet bajtů | počet zapsaných bajtů |
| REVIVE | proces k oživení (jeho požadavek na I/O byl uspokojen), počet předaných bajtů | bez odpovědi |
| UNPAUSE | Některý proces čekal v read() a byl mu doručen signál. Zajisti návrat z read() s chybovým kódem EINTR. Parametr je číslo procesu. | . |
| FORK, EXIT, SETUID, SETGID | Informace od MM, že je něco třeba změnit ve fproc[]. Může se jednat o zkopírování informací z jednoho slotu do druhého (fork) nebo o úpravu položek v zadaném slotu. Parametrem zprávy je informace, co se má změnit, slot, kterého se to týká a nová hodnota. Pokud jde o fork, jsou parametrem dvě čísla slotů. | OK |
Tab. 5.1.
Svazky souborového systému lze libovolně montovat na sebe. Jedinou podmínkou, aby zařízení mohlo být použito pro uložení svazku souborového systému je, aby k němu byl k dispozici ovladač blokového zařízení. To je samozřejmě splněno pro ovladače floppy, pevného disku i ramdisku. Standardní rozložení bloků na svazku souborového systému je vyobrazeno na obr. 5.1.
![]()
Obr. 5.1.
V dalším textu se budeme setkávat s pojmy blok a zóna. Blok budeme chápat jako nejmenší kvantum dat přenášené mezi blokovým zařízením a pamětí (jeho velikost určena konstantou na 1024 byte). V pseudokódech narazíme rovněž na pojem zóna. Zóny sestávají z určitého počtu bloků (vždy mocnina 2) a slouží jako alokační jednotky pro snížení velikosti bitmap volných zón a omezení fragmentace souborů. Pro jednoduchost ale budeme v první implementaci předpokládat. že zóna sestává z jednoho bloku, tedy budeme pojmy zóna a blok považovat za ekvivalentní..
Nyní se ale vraťme ke struktuře souborového systému.
Boot block obsahuje kód, který je použit tehdy, když je ze zařízení zaváděn systém. V takovémto případě je boot blok zaveden to paměti BIOSem a je mu předáno řízení. Na médiích, z nichž systém zaváděn není, je zaváděcí blok nevyužit.
Superblok obsahuje informace o souborovém systému uloženém na médiu. Jeho formát lze popsat následující strukturou:
struct super_block {
inode_nr s_ninodes; /* pocet inode */
zone_nr s_nzones; /* pocet zon na svazku */
unshort s_imap_blocks; /* pocet bloku, ktere zaujima bitmapa i-nodes */
unshort s_zmap_blocks; /* pocet bloku, ktere zaujima bitmapa zon */
zone_nr firstdatazone; /* cislo prvni datove zony */
short int s_log_zone_size; /* pocet bloku v zone (log2 pomeru blok/zonu, */
/* => snadny prepocet bitovym posuvem) */
file_pos s_max_size; /* maximalni delka souboru */
int s_magic; /* magicke cislo identifikujici platny superblok */
};
Seznam superbloků namontovaných svazků je udržován v paměti (pole super_block[]).
Bitmapa i_node bitmap určuje, které pozice v následném seznamu i-nodes jsou zaplněny. Počet bitů bitmapy odpovídá počtu i-node v seznamu i-nodes (položka s_ninodes superbloku). Počet bloků, která tato bitmapa zabírá je dán položkou s_imap_blocks. Také bitmapy i-node a zón jsou pro zrychlení přístupu udržovány v paměti (je na ně odkaz z příslušného záznamu pole super_blocks[]).
Dále následuje bitmapa volných bloků. Každému bloku (počínaje superblock.firstdatazone) přísluší jeden bit, který určuje, zda je blok doposud volný, nebo je obsazen daty některého souboru.
Seznam i-nodes sestává ze záznamů d_inode, kde každý i-node udržuje informace o jednom souboru, adresáři či speciálnímu souboru:
struct d_inode {
mask_bits i_mode;
uid i_uid;
file_pos i_size;
real_time i_modtime;
gid i_gid;
links i_nlinks;
zone_nr i_zone[NR_ZONE_NUMS];
}
FS obsahuje tabulku inodes[] těchto struktur, ve které jsou uloženy
inode souborů, se kterými právě některý proces pracuje.
Datové bloky nemusí nutně začínat bezprostředně za tabulkou inode. Namísto toho je číslo prvního datového bloku uvedeno v superbloku. Takto může za tabulkou inode vzniknout mezera, kterou bude souborový systém obcházet, a která může být využita např. pro umístění obrazu systému na zaváděcí disketě.
Stejně jako MM obsahuje i FS svou část tabulky procesů, fproc[NR_PROCS]:
struct fproc {
mode_t fp_umask; /* mask set by umask system call */
struct inode *fp_workdir; /* pointer to working directory's inode */
struct inode *fp_rootdir; /* pointer to current root dir (see chroot) */
struct filp *fp_filp[OPEN_MAX];/* the file descriptor table */
uid_t fp_realuid; /* real user id */
uid_t fp_effuid; /* effective user id */
gid_t fp_realgid; /* real group id */
gid_t fp_effgid; /* effective group id */
dev_t fp_tty; /* major/minor device #of controlling tty */
int fp_fd; /* place to save fd if rd/wr can't finish */
char *fp_buffer; /* place to save buffer if rd/wr can't finish*/
int fp_nbytes; /* place to save bytes if rd/wr can't finish */
char fp_suspended; /* set to indicate process hanging (i/o could not have */
/* been finished yet (due to data unavailability) */
char fp_revived; /* set to indicate process being revived (for PIPES)*/
char fp_task; /* which task is proc suspended on */
} fproc[NR_PROCS+NR_SERVS_NR_TASKS];
/* Field values. */
#define NOT_SUSPENDED 0 /* process is not suspended on pipe or task */
#define SUSPENDED 1 /* process is suspended on pipe or task */
#define NOT_REVIVING 0 /* process is not being revived */
#define REVIVING 1 /* process is being revived from suspension*/
Jak vidíme, obsahuje tato tabulka zejména položky identifikující aktuální
a root adresář file systemu, pole deskriptorů souborů a místo pro uložení
parametrů volání, které nemůže být uspokojeno okamžitě.
Pro urychlení přístupu k disku implementuje FS mechanismus vyrovnávací paměti (cache). Cache je společná pro všechna bloková zařízení, I/O ze znakových zařízení cache obchází. Jedná se v podstatě o pole bufferů spojených do oboustranně zřetězeného seznamu. Každý prvek seznamu obsahuje jednak hlavičku popisující, jaký blok se v příslušném bufferu právě nachází a dále buffer pro vlastní blok dat. Jestliže souborový systém potřebuje přečíst nebo zapsat blok, obrací se s tímto požadavkem zásadně na cache, ne přímo na ovladač disku. Cache určí, zda je příslušný blok v paměti a o přístup na disk žádá ovladač určeného zařízení jen tehdy, když blok ještě načten nebyl. Podobně u zápisu je blok zapsán na disk až tehdy, kdy musí být jeho buffer opětovně použit pro jiné účely. Pro kritická data, jako jsou např. inody či bitmapy volných zón, samozřejmě existuje i možnost vynutit okamžitý zápis na disk.
Bloky cache jsou položkami pole buf[NR_BUFS]. Jejich počet je tedy určen při kompilaci systému. Jednotlivé bloky jsou obousměrně zřetězeny od MRU (most recently used) k LRU (least recently used). Mimo to jsou použité buffery řazeny do pomocných front podle čísla bloku, který obsahují. Máme tedy implementovánu pomocnou hashovací tabulku, která ukazuje na začátky těchto front a výrazně tím urychluje proces vyhledání bloku v cache (nebo rozhodnutí o jeho nepřítomnosti). Hashovací funkce, podle které se bloky rozdělují do těchto seznamů, může být obecná; pro jednoduchost použijeme dělení do zbytkových tříd podle čísla bloku (bez ohledu na číslo zařízení, ze kterého blok pochází). Provázání bufferů v cache je vyobrazeno na obr. 5.2.
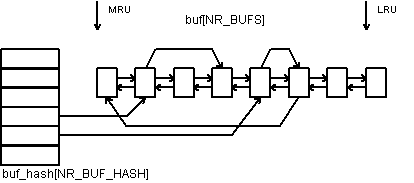
Obr.5.2
Struktura bufferu, sestávající z hlavičky a místa pro samotná data je definována takto:
struct buf {
/* Data portion of the buffer. Provides different views to data contained in block */
union {
char b__data[BLOCK_SIZE]; /* ordinary user data */
struct direct b__dir[NR_DIR_ENTRIES]; /* directory block */
zone_nr b__ind[NR_INDIRECTS]; /* indirect block */
d_inode b__inode[INODES_PER_BLOCK]; /* inode block */
bitchunk_t b__bitmap[BITMAP_CHUNKS]; /* bit map block */
int b_int [INTS_PER_BLOCK]; /* block full of integers */
} b;
/* Header portion of the buffer. */
struct buf *b_next; /* used to link all free bufs in a chain */
struct buf *b_prev; /* used to link all free bufs the other way */
struct buf *b_hash; /* used to link bufs on hash chains */
block_t b_blocknr; /* block number */
dev_t b_dev; /* major | minor device where block resides */
char b_dirt; /* CLEAN or DIRTY */
char b_count; /* number of users of this buffer */
} buf[NR_BUFS];
/* A block is free if b_dev == NO_DEV. */
#define NIL_BUF ((struct buf *) 0) /* indicates absence of a buffer */
V hlavičce bufferu (položka b_count) se eviduje, kolik odkazů na příslušný blok v systému existuje. Když tento počet klesne k nule, přesune se blok na konec fronty (zpravidla před MRU, ale jsou výjimky). Některé bloky (např. bloky s tabulkou volných zón) nají b_count prakticky stále nenulový, jelikož s nimi FS pracuje po celou dobu běhu systému (resp. po dobu namontování příslušného svazku). V okamžiku, kdy jsou již všechny bloky zaplněny a je třeba vybrat kandidáta na odstranění, vyhledává se od LRU k MRU s tím, že bloky s nenulovým počtem použití se ignorují.
Scénář přístupu k blokům tedy vypadá následovně. File system určí číslo bloku, se kterým chce pracovat (číst nebo zapisovat). Poté voláním vnitřní funkce get_block() požádá cache o pointer na buffer s daty požadovaného bloku. Ta buffer buď vlastní a tehdy jen zvětší v jeho hlavičce položku b_count a vrátí pointer na blok, nebo požádá ovladač zařízení, na kterém se blok nachází, o jeho načtení. V ovladači může dojít ke krátkodobému zablokování v době, kdy se vystavují hlavy a čeká se na dokončení DMA, takže je v té době zablokován i celý FS (než mu dojde odpověď na zprávu od ovladače disku) a tedy mohou v této době běžet jiné (i uživatelské) procesy.
Při vyhledávání bufferu, do ktrerého se má blok načíst, se postupuje v seznamu od LRU, až se najde blok, který není právě používán (b_count=0). Jestliže je v hlavičce indikováno (položka b_dirty), že data bloku byla modifikována, je nejprve proveden zápis původního obsahu bufferu na disk.
File system musí v okamžiku, kdy již data z bloku nepotřebuje (obecně co nejdříve), blok uvolnit vnitřním voláním put_block(). Pokud ovšem data v bloku zmodifikoval, musí předtím nastavit v hlavičce bufferu položku b_dirty. Volání put_block() dekrementuje b_count v hlavičce a na základě parametru, který identifikuje charakter v bloku obsažených dat, přesune blok v obousměrném seznamu na stranu LRU nebo MRU podle toho, zda se předpokládá, že blok bude v krátké době znovu vyžádán. U zvlášť důležitých dat rovněž vynutí okamžitý zápis bufferu na disk. Symbolické konstanty indikující charakter dat v bloku a jejich význam lze najít v souboru BUF.H.
Adresáře se v TUOXu jeví jako běžné soubory. Platí konvence, že inode s číslem 1 reprezentuje hlavní adresář. Soubor adresáře sestává z položek dir_struct, které informují o v něm obsažených souborech a podadresářích:
struct dir_struct {
inode_nr d_inum;
char d_name[NAME_SIZE];
};
Kromě běžných souborů a adresářů musí FS podporovat práci se speciálními soubory (ovladači zařízení). I ty mají svůj inode, mapa alokovaných bloků však pro ně nemá smysl, takže v poli inode.i_zone[0] je uloženo major a minor číslo zařízení, které je prostřednictvím souboru zpřístupněno. Major číslo slouží jako index do tabulky dmap[] (viz DEV.H), která obsahuje pointry na rutiny zabezpečující volání ovladače pro jednotlivé činnosti podporované ovladačem (tyto typické činnosti jsou v principu pro všechny ovladače shodné). V UNIXu tyto odkazy již reprezentují samotné rutiny ovladače. Jelikož je však TUOX modulární a my to musíme při zachování co největší podobnosti s UNIXem respektovat, existuje zde meziúroveň univerzálních funkcí, na které jsou odkazy z dmap[] nasměrovány a které provádějí samotné zaslání (send_recv) jim předaných zpráv příslušnému tasku. Minor číslo zařízení se předává tomuto tasku jako jeden z parametrů zprávy. Major číslo také odpovídá pozici příslušného ovladače v tabulce proc[].
Server FS mnohdy nemůže vyřídit požadavek procesu okamžitě. Může např. čekat na nastavení hlav, nebo požadovaná data (třeba z terminálu) zatím vůbec nejsou k dispozici. V takovémto případě musí FS klientský proces zablokovat, vrátit se do hlavní smyčky a čekat na další požadavky. Předtím si však do své části tabulky procesů k zablokovávanému procesu (položky fp_fd, fp_buffer, fp_nbytes) poznačí parametry zprávy, k jejímuž zpracování se bude později třeba vrátit a nastaví (ve fproc[]) u procesu flag, že je suspendován. Zablokování klientského procesu proběhne tím, že mu není zaslána odpověď na zprávu. Proces bude odblokován tehdy, až zašle ovladač zařízení, se kterým klient hodlal komunikovat, zprávu o připravenosti (REVIVE). Na tu FS reaguje tak, že zjistí, který ovladač připravenost hlásí a najde v tabulce procesů, kdo službu na daném ovladači požadoval. Pak již odblokuje nalezený proces zasláním zprávy s tím, že předtím dokončí rozpracovanou operaci (nakopíruje požadovaná data do adresového prostoru příslušného procesu). Kopírování se děje jen v případě přístupu k diskům, terminálový task je specifický v tom, že kopírování dat uživatelskému procesu provádí sám task (s využitím funkce poskytované jádrem).
Odblokovávání procesů je náročnější v případě rour. Může totiž být i několik procesů které jsou suspendovány při čekání na data z roury, jež je doposud prázdná. Jestliže do roury nyní proces, který ji má otevřenu pro zápis, zapíše, je třeba všechny zablokované procesy čekající na data odblokovat. K tomu je určen pomocný mechanismus, využívající položky revived v záznamu fproc[]. Volání write() totiž testuje, zda je soubor, do kterého se zapisuje, rourou a pokud ano, vyhledává procesy, které jsou zablokovány při čekání na data z této fronty. Jestliže takové procesy najde, nastaví u nich flag REVIVING. V hlavní smyčce FS se vždy nejprve zkoumá, zda některý proces nemá nastaven flag REVIVING a pokud ano, dokončí se jeho požadavek (parametry se naleznou ve fproc[]). Až tehdy, když žádný takový proces není, volá se receive(ANY) pro převzetí dalšího požadavku o službu od ostatních procesů.
Na závěr ještě poznamenejme, že pro dosažení shodného chování s UNIXem musí FS umět zpracovat zprávu UNPAUSE, která se mu doručuje tehdy, když byl nějaký proces zablokován a byl mu zaslán signál. V takovémto případě musí FS umět ověřit, zda proces nebyl zablokován v čekání na dokončení volání read() a pokud ano, zajistit návrat z tohoto volání s chybovým kódem EINTR.
Zavádění systému TUOX probíhá v první fázi z diskety. Bootovací disketa obsahuje boot sektor, který BIOS zavede do paměti a spustí jej. Zbytek diskety obsahuje image systému, sestávající z obrazu jádra (vč. tasků a loaderu - funkce main() ), file systemu, memory manageru a procesu Init. Na disketě je rovněž na definovaném místě tabulka sizes[], která udává velikosti jednotlivých komponent systému. Počáteční adresa, na které v paměti začíná jádro, je fixní (popř. určena hodnotou na definovaném místě zaváděcí diskety). Úkolem zavaděče je jednak zavést všechny moduly systému do paměti a jednak zajistit úvodní naplánování všech systémových procesů a tasků. První část je prováděna z kódu obsaženého v boot sektoru (popř. i dalších, nevejde-li tam), poté se předá řízení inicializačnímu loaderu implementovanému ve funkci main() přilinkované ke kernelu, která je současně vstupním bodem systému.
Zaváděcí disketa mimoto obsahuje kořenový adresář souborového systému. Její formát odpovídá formátu souborového systému popsaného v kap. 5.1, v mezeře mezi tabulkou inode a první datovou zónou souborového systému je uložena image systému.
Jednotlivé moduly jsou zaváděny do paměti vždy od hranice paragrafu v tomto pořadí: kernel+tasky, MM, FS, Init. Za nimi je vyhrazen kus místa pro RAM disk (velikost dána konstantou na dohodnutém místě zaváděcí diskety). Další paměťový prostor je již určen procesům uživatele.
Tabulka, která udává umístění příslušných komponent systému v paměti, musí být k dispozici při inicializaci memory manageru a ovladače ramdisku.
Úkolem zavaděče je rovněž úvodní naplánování všech systémových procesů a tasků, aby tyto mohly provést své inicializační části. To se děje ve funkci main(), která je z důvodu snadného přístupu do systémových struktur slinkována s kernelem a je vyvolána po zavedení image systému do paměti.
Po provedení inicializačních částí tasků a serverů (a případně jádra, pokud bude inicializaci vyžadovat) již bude systém sám o sobě schopen běhu. Při inicializaci systému (po zavedení jeho obrazu do paměti) je tedy postupně nutné vykonat následující akce:
Po startu plánovače tasky a servery postupně provedou svůj inicializační kód a zablokují se čekaje na zprávu. Vzpomeňme, že běh tasků není schedulerem přerušován, inicializační kódy tasků a serverů tedy proběhnou jeden po druhém. Pak se již dostane ke slovu proces Init.
Jádro plní dvě základní funkce: implementuje mechanismus doručování zpráv a řídí plánování procesů. Mimo to obsahuje nejnižší úroveň obslužných rutin přerušení a zajišťuje převod hardwarového přerušení na zaslání zprávy příslušnému tasku. Mechanismus předávání zpráv i plánovač již byly popsány ve dřívějších sekcích, proto si zde uvedeme pouze poznámky sloužící jako vodítko pro implementaci.
Doposud jsme se v souvislosti s předáváním zpráv odkazovali na primitiva SEND, RECEIVE a SEND_RECV. Jejich skutečná implementace je realizována pomocí maker, jež jsou využívána ostatními vrstvami systému, včetně systémových knihoven. Makro se rozvine na vyvolání softwarového přerušení, které je nasměrováno na dále popisovanou rutinu jádra s_call. Parametry volání se předávají v registrech. Jde zejména o informaci o typu primitiva (SEND/RECEIVE/SEND_RECV), identifikace procesu, kterému se má zpráva předat, resp. od kterého se má zpráva převzít a pointer na buffer se zprávou (near pointer, v rámci adresového prostoru právě běžícího procesu). Pro určení odesílatele zprávy a přepočet virtuální adresy bufferu se zprávou potřebujeme určit proces, který primitivu zavolal. Tímto procesem však může být jedině právě běžící proces, jehož identifikaci v podobě pozice v tabulce procesů najdeme v proměnné cur_proc.
Kernel sestává ze tří zdrojových souborů: PROC.C, MPX88.C a KLIB88.C (viz pseudokódy). Poslední dva jsou téměř celé napsány v assembleru, PROC.C je stejně jako zbytek systému v C.
Kernel obhospodaruje následující globální proměnné:
int cur_proc
- index právě běžícího procesu v tabulce proc[]
struct struct_proc *proc_ptr; /* (&proc[cur_proc]) */
- pointer na prvek proc[] patřící právě běžícímu procesu
struct struct_proc *bill_ptr;
- pointer na (uživatelský) proces, kterému se bude účtovat tik hodin
struct struct_proc *rdy_head[NQ];
- pointer na pole začátků front běhuschopných procesů
struct struct_proc *rdy_tail[NQ];
- pointer na pole konců front běhuschopných procesů
unsigned busy_map;
- bitmapa: každý bit odpovídá jednomu tasku. Jednička na příslušném bitu
indikuje, že se obslužná rutina přerušení svázaného s daným taskem pokoušela
předat tasku zprávu, ale task byl zaneprázdněn. Proto se musí funkce k_interrupt()
při dalším přerušení pokusit zprávu doručit znovu. Zpráva je mezitím uložena
na odpovídající pozici pole task_mess[NR_TASKS].
message int_message;
- buffer pro zprávu která vzniká v době přerušení a je určená některému tasku
message task_mess[NR_TASKS];
- pole pro uložení zpráv o přerušení, které dosud nemohly být doručeny
příslušným taskům z důvodu jejich zaneprázdněnosti.
int sig_procs
- počet procesů, jimž má být doručen signál
Jednotlivé moduly obsahují zejména dále popsané funkce
Nejnižší úroveň přepínání procesů a obsluhy přerušení
Slouží k uložení a obnovení registrů do/z tabulky procesů a to do/z pozice, na kterou ukazuje cur_proc. Jelikož se mezi voláním k_save a k_restart může hodnota cur_proc změnit (pokud byl zavolán plánovač), lze takto provádět přepínání mezi procesy. Plánovač zajistí pouze nastavení cur_proc, samotné uschování původních obsahů registrů a jejich nové naplnění provedou k_save a k_restart. (Rutina k_save navíc nastavuje zásobník na zásobník kernelu). Pokud v okamžiku, kdy je vyvolán k_restart, není žádný proces schopen běhu (cur_proc=IDLE), provede se odskok na zvláštní smyčku, ve které se povolí přerušení a instrukcí wait se čeká na další přerušení, které způsobí, že se některý task stane schopným běhu.
Protože je rutina k_save volána vždy při vstupu do jádra, nastavuje se v ní rovněž DS tak, aby se zpřístupnily globální proměnné jádra.
Rutina k_restart končí instrukcí iret, která způsobí obnovení původního stavu přerušení, na stacku musí být předtím připraveno nové CS:IP:FLAGS.
obsluha SW přerušení pro předávání zpráv. V ní se uschovají registry (k_save), z předaných hodnot (caller=cur_proc, destination, typ požadavku: SEND/RECEIVE/SEND_RECV, ptr na buffer se zprávou) se zformulují parametry (vytvoří se zásobník obsahující tyto parametry) pro C-funkci sys_call() a tato funkce se zavolá. Ve funkci může mj. dojít k přeplánování, což se projeví změnou hodnoty proměnné cur_proc. Po návratu se volá k_restart, která nastaví registry podle právě prováděného procesu (proměnná cur_proc).
k_save, zformulování zprávy pro příslušný task v int_message, volání C-funkce k_interrupt(), k_restart
k_save, volání C-funkce keyboard() [HW závislá část TTY, tam přečtení scan code, převod na ASCII a pokus o zaslání zprávy HW nezávislé části ovladače TTY], k_restart
k_save, volání C-funkce rs232(portNo) [HW závislá část TTY, tam přečtení znaku z portu, pokus o zaslání zprávy HW nezávislé části ovladače TTY], k_restart
Nevyužitá přerušení jsou nasměrována na tuto obslužnou rutinu. Volá se k_save, provede se výpis chybového hlášení, k_restart
Implementuje skupinu pomocných nízkoúrovňových funkcí, které mohou být volány tasky (připomeňme, že jádro je s tasky slinkováno). Jde např. o funkce podporující kopírování bloků (lineární) paměti, povolování přerušení, vstup/výstup z portů atd., viz pseudokód. Funkce jsou napsány převážně v assembleru, parametry funkcí se předávají přes zásobník ve volací konvenci jazyka C.
Vyšší úroveň obsluhy přerušení (převod na zprávy), mechanismus doručování zpráv, plánovač
voláno z nejnižších vrstev obsluhy přerušení (MPX88.C). Pokusí se určenému tasku zaslat zprávu a tím dosáhnout jeho naplánování. Zpráva se zde ovšem nezasílá běžnou primitivou SEND, která může způsobit zablokování odesílatele do doby, kdy bude adresát schopen převzít zprávu, ale zvláštní funkcí mini_send(), která indikuje úspěch odeslání jako návratový kód. Jako odesílatel zprávy se namísto pozice odesílatele v proc[] uvádí zvl. kód HARDWARE. V případě, že se předání zprávy nepodařilo (task byl zaneprázdněn), nastaví se příslušný bit v busy_map a zpráva se uschová do task_mess[]. Navíc se, pokud šlo o zprávu pro clock task, zvýší hodnota proměnné lost_ticks, aby později bylo možné opožděné přerušení zkompenzovat. Pokud se zpráva odeslala úspěšně, zruší se příslušný bit v busy_map, byl-li nastaven.
Ať se již zaslání zprávy podařilo nebo ne, prochází se poté ve smyčce busy_map a vždy se pokusíme odeslat zprávu těm taskům, kterým měla a doposud nemohla být doručena. V případě úspěšného doručení se samozřejmě nuluje příslušný bit busy_map. Protože v mini_send() mohlo dojít k naplánování tasku s vyšší prioritou, než má právě běžící proces, zkoumáme dále, zda právě běžící proces je uživatelským (nebo dokonce idle). Pokud tomu tak je a ve frontě čeká nějaký task schopný běhu (rdy_head[TASK_Q]!=NULL), provede se přeplánování voláním funkce pick_proc(). Ta může změnit hodnotu cur_proc a tím rutina k_restart provede po návratu z k_interrupt() přechod k jinému procesu, než běžel doposud.
řeší předávání zpráv a je přímo volána již popsanou rutinou s_call. Součástí těla funkce je test, zda odesílatel a příjemce zprávy leží ve stejné, popř. přilehlé vrstvě (jinak se komunikace neumožní). V případě zasílání zprávy uživatelským procesem (resp. jeho knihovanami) se umožní pouze volání primitiva SEND_RECV. Pro zaslání zprávy se zavolá funkce mini_send(caller,dest,mess_ptr), pro převzetí pak mini_rec(caller,src,mess_ptr).
pokus o zaslání zprávy od zdrojového procesu k cílovému procesu. Pokud je cílový proces zablokován čekáním na zprávu (od tohoto zdroje), zpráva se nakopíruje do jeho adresového prostoru a cílový proces se odblokuje (zruší se flag RECEIVING v tab. procesů a volá se funkce ready(), kterou prohlásíme proces za schopný běhu). Pokud cílový proces nečeká na převzetí zprávy od daného zdroje a nejedná se o "zprávu od hardware", zdrojový proces se přidá do fronty čekajících na odeslání zprávy a zablokuje se (volá se unready() a nastaví se flag SENDING v tab. procesů). Jednalo-li se o "zprávu od hardware" (tj. pokus o zaslání zprávy některému tasku z obslužné rutiny přerušení, kdy je odesílatel namísto pozicí v tabulce procesů identifikován konstantou HARDWARE), žádné zablokování a vkládání do fronty se neděje, ale pouze se vrací chybový kód.
Dále se ve funkci provádí několik pomocných testů pro udržení konzistence systému v případě chybných parametrů, viz pseudokód.
pokus procesu o převzetí zprávy od zdrojového procesu. Pokud je zpráva již ve frontě, odblokuje se její odesílatel (zruší se flag SENDING a volá se ready()) a zpráva se předá. Pokud žádná zpráva ve frontě nečeká, volající proces se zablokuje (volání unready(), nastavení flagu RECEIVING). V závěru funkce je navíc vhodné místo pro obsluhu signálů, pokud byly mezitím nějaké vygenerovány. Testuje se, zda kernel nemá zaregistrovány nevyřízené signály a zda volání receive nevyvolal memory manager (kterému zpracování signálů přísluší). Pokud tomu tak je a není pro MM právě žádná jiná zpráva, volá se zvláštní funkce inform() (součást system tasku), která zajistí předání zprávy žádosti o obsloužení signálu (KSIG) memory manageru.
Hlavní rutina plánovače. Nastavuje cur_proc (a proc_ptr) na proces s nejvyšší prioritou, který má dále běžet. Pokud žádný proces není schopen běhu, nastaví se cur_proc=IDLE a proc_ptr na jinak nevyužitý slot tabulky procesů (proc[IDLE]), aby bylo kam uschovat registry při dalším přerušení. Proměnná bill_ptr se stále udržuje ukazující na proces, kterému má být účtován následující tik hodin.
připojí proces, který byl prohlášen za schopný běhu, na konec příslušné fronty
odstraní proces, který nadále není schopen běhu z příslušné fronty procesů schopných běhu
rutina vyvolávána periodicky clock taskem při vypršení časového kvanta. Jestliže je ve frontě připravených uživatelských procesů více než jeden proces, proces z čela fronty se přesune na její konec. Tím se dostává ke slovu další uživatelský proces. Následně se volá pick_proc() pro naplánování procesu s nejvyšší prioritou.
Hlavním úkolem shellu je interaktivně komunikovat s uživatelem a umožnit mu spouštět programy. Spouštět lze jednak binární spustitelné programy, jednak skripty, které shell interpretuje. Shell podporuje přesměrovávání standardního vstupu, výstupu a chybového výstupu jednotlivých programů (>,<,2>,2<,>>,<<, mix stderr a stdout) a řetězení programů do kolon. Poslední zmíněná vlastnost bude realizována přes roury, pokud je file system podporuje, v opačném případě zajistí shell přesměrovávání do dočasných souborů a postupné spouštění programů kolony. Dočasné soubory vznikají v adresáři, na který ukazuje proměnná TEMP.
Shell rovněž umožňuje nastavovat systémové proměnné, které budou předávány jednotlivým spouštěným programům jako proměnné prostředí (environment). Proměnné se nastavují příkazem SET (bez parametrů provede výpis hodnot proměnných). Na proměnné se lze odkazovat řetězcem ve tvaru $VARNAME, který shell v době interpretace zamění za příslušné proměnné.
Nesystémové proměnné mají implicitně platnost pouze v rámci aktuálního shellu. Pokud chceme, aby byly předávány spouštěným programům, je třeba je exportovat pomocí příkazu export.
Jelikož je shell běžným programem, může být spuštěn jiným shellem. Pokud tak učiníme, můžeme jako parametr shellu uvést jméno skriptu, který má být novým shellem vykonán.
Shell používá (a automaticky udržuje) hodnoty několika systémových proměnných:
HOME - absolutní cesta k domovskému adresáři právě přihlášeného uživatele
USER - jméno právě přihlášeného uživatele
PATH - seznam cest, kde má shell hledat spouštěné programy. Cesty se oddělují dvojtečkou
ERRNO - chybový kód naposled spuštěného programu
PWD - aktuální adresář
PID, PPID - pid aktuálního a rodičovshého shellu
PS1, PS2 - prompt
Skript je program v textové formě, který je určen k tomu, aby byl shellem interpretován. Skripty mohou být zadávány buď interaktivně přímo na příkazový řádek shellu, nebo mohou být uloženy do zvláštního souboru, který se z pohledu uživatele spouští stejně jako binární program. Skript se běžně vykonává novou instancí shellu, v případě, že je však spouštěn příkazem ". scriptname", vykoná se v rámci téže instance shellu. To se využije zejména v případech, kdy ve skriptu potřebujeme nastavit systémové proměnné, jejichž nastavení by se nám v případě vykonávání skriptu novým shellem s ukončením tohoto shellu ztratilo a nijak by se do rodičovského shellu nepromítlo.
Bezprostředně po spuštění shell automaticky vykonává skript .login, pokud takovýto soubor najde v aktuálním adresáři.
Výhodné je rovněž zavést mechanismus, který by umožnil zadefinovat makra pro často užívané příkazy.
Jazyk skriptů může být zadefinován libovolně, měl by však obsahovat následující prvky:
Př:
for i in (1,2,3) do
echo $i
done
while ($? -gt 0) do
echo $1
shift
done
příkazy if ... then ... else ... fi, příp. case ... esac
pozn.: Musí být umožněno vkládat i znaky, které mají speciální význam (např. $), jako běžné znaky (nejlépe jejich uvozením vhodným ESC znakem, jako je např. \).